
Self-supervised learning is our best shot
The most popular type of machine learning is Supervised machine learning. Supervised machine learning works in this manner, you gather lots of human-labeled data, these labels that the humans annotate work as “points of interests” or “guides” for the machine learning system to use such that it can learn something useful about the data, for example annotating a picture of a cat with label “cat”, tells the model that this picture contains features that are distinct to cats so try and figure out those features, annotating objects within a picture with bounding boxes guides the model that within these boundaries there is something of interest so try and learn how to figure these boundaries out.
Even though this paradigm looks logical and it indeed provides us with very capable models, it falls short on several aspects, let’s start off with scalability, supervised learning requires human-labeled data, this manual process of labeling data points is very expensive and time-intensive process, take Imagenet as an example, Imagenet is a huge standard images database with over 14,000,000 labeled images over 20,000 classes. How long did it take to create such a dataset? 22 years. Also 14 million images might seem like lots of data but that’s a fraction of what is available on the internet. Another thing to put in mind is that 20,000 classes is a humble number compared to the amount of classes the universe contains, a model that can differentiate between 20,000 classes only still has so much to know about the world. Main point here is that there is so much data left to be used which supervised learning cannot exploit due to the manual labeling process.
Another interesting insight is the comparison between current machine learning systems and humans when it comes to how quickly they learn something new. It would take a child very few examples of dogs to be able to pick out almost any dog from a scene, on the other hand deep learning models need thousands or millions of examples for such “trivial” tasks. The hypothesized reason is that, humans normally have background knowledge of how the worlds works (a model of the world) that helps them quickly learn new things, a child learning about dogs probably has previous knowledge of what objects are, what a living creature is, how domestic animals might look like, etc., knowledge that has been accumulated implicitly through observation and interactions with the world, and this knowledge helps him learn about dogs so quickly with just a few examples. The argument here is that, machine learning models could benefit from such background knowledge on “how the world looks like and works” before solving a specific supervised task like classification. This is when self supervised learning comes in.
The goal of self supervised learning is to learn some kind of representation of the world that can be used in other specific tasks later, one area that has benefited from this is natural language processing, models like BERT go through a self supervised pretraining phase before being used on a specific supervised task such as sentiment analysis. So how does self supervised learning work? how does it help the model learn to represent the world? first let us elaborate more on the learning a representation thing, what usually happens is that we want our model given an input x to output a vector (that we will call h) that captures the essential information and structure of the input, this h vector is our representation of input x, we can then use the h vector (our representation) in other “downstream” supervised tasks.
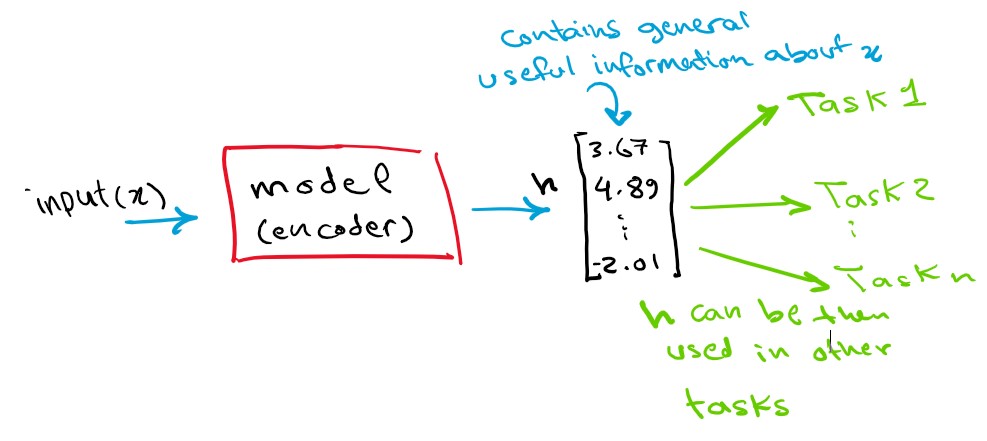
This h representation should be consistent with other inputs’ representations as well, for example an h vector for a cat should be similar to another cat representation but also very different to an elephant’s and wildly different to a car’s representation vector.
So how do we get a model to learn such representations? one general way that worked very well in natural language processing is the “fill in the blanks” approach. This is better illustrated with a visual example:
![]()
Consider a video (a video is basically a sequence of images/frames), approach (A) try to predict what happens next in the video (future frames) given the past frames, approach (B) try to fill out the missing frames given the known frames, approach (C) fill out the missing parts of the frames themselves, and fill out any missing frames.
The same example can be adapted to natural language processing, (A) predict the sentence continuation, (B) try to fill out the missing words, (C) try to fill out the missing characters or words.
Creating a dataset for such tasks is easy and does not require manual labeling, little human supervision will be needed to decide how will the input be altered and what should the model predict (a missing word? how many words should we hide/mask etc.) but when all of this is figured out it is easy to automate the dataset generation process. The tasks themselves are very general and therefore provide a very rich signal to the model, the data itself provides the supervision for the machine learning model, that’s why it is called self supervised. If a model can predict how a video continues then it has learned a lot about the world and its physics, such knowledge will be useful when used in any specific task in the future.
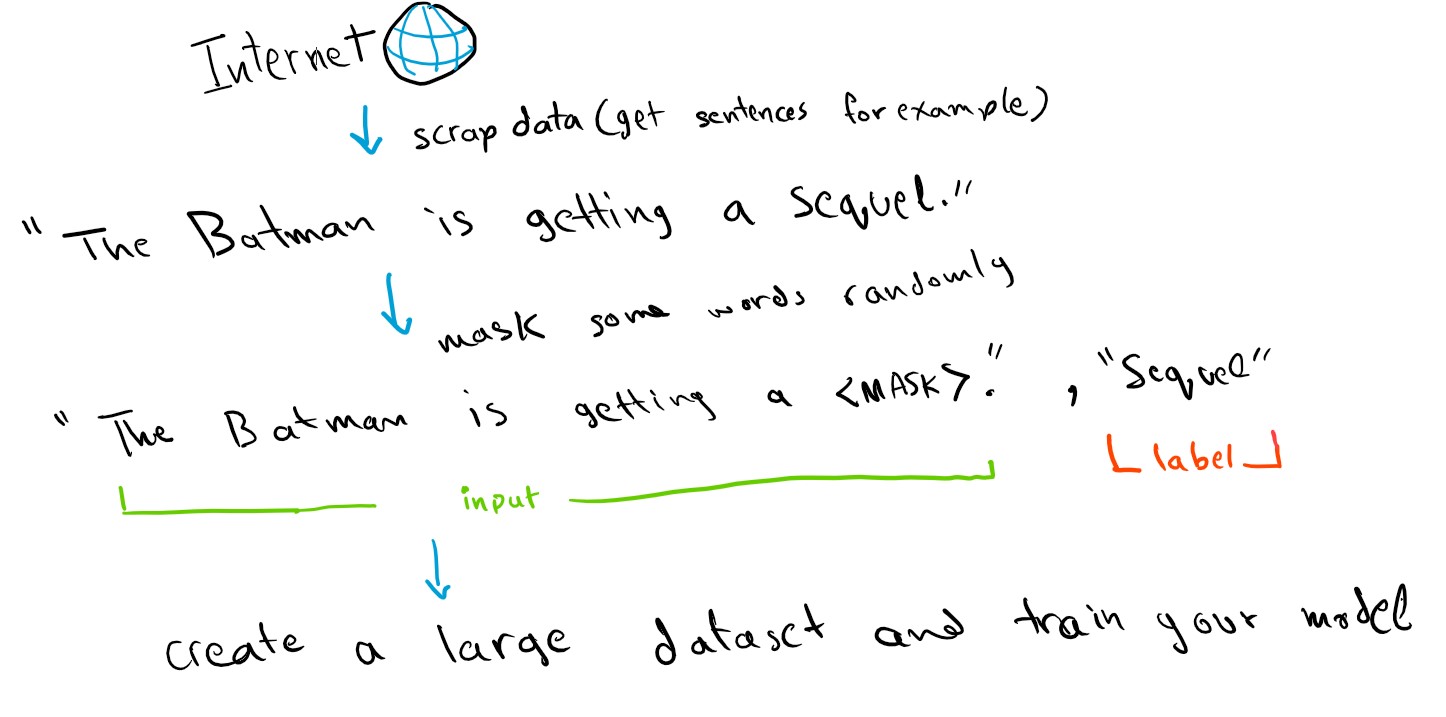
The way this model is trained is that it encodes the input into representation (h), then this representation is fed into another usually small neural network that we will call task head, this small neural network is responsible for projecting this representation into the task’s output (for example if the task is to predict a missing word then the task head will act as a multi-class classifier over the vocabulary), the task head will be different depending on the task the model is being pretrained on. After the model’s error gets lower on the tasks and converges, the intermediate outputs of the model can be used as representations (h) of the inputs that will be used in the downstream supervised tasks, and the task head can be discarded.
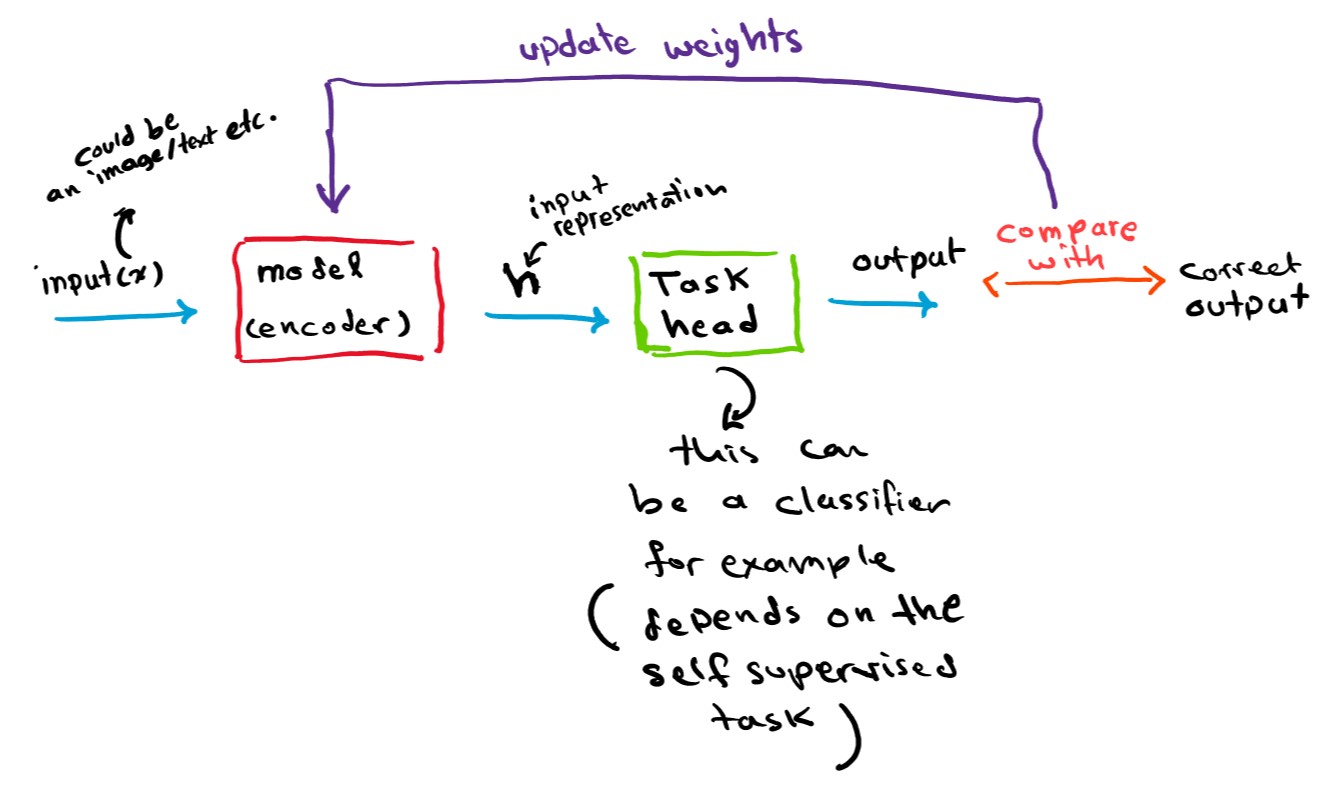
If it isn’t obvious how such general tasks can help the model with more specific tasks later, consider the example of pretraining a language model to do the previous general tasks, then adapt it to classify toxic and non-toxic comments (supervised task), the model has already been trained on millions (if not billions since the data doesn’t need to be manually labeled therefore generating data is not an issue anymore) of sentences where it had to predict missing words and predict if a sentence is a logical continuation to the other and other general tasks. The model would not be able to predict the missing words without understanding the sentence the words are in, it will also figure out that the sentiment of the sentence has an influence on the words used, which is exactly what is needed for a model to classify toxic and non-toxic comments. Point is, the model will learn lots of general features in the pretraining phase, while the specific supervised task will require probably only a subset of these learned features.
As I mentioned before, the “fill in the blanks” approach is very successful in natural language processing, BERT is a very good example for that; on the contrary computer vision models do not show much success with this approach (so far).
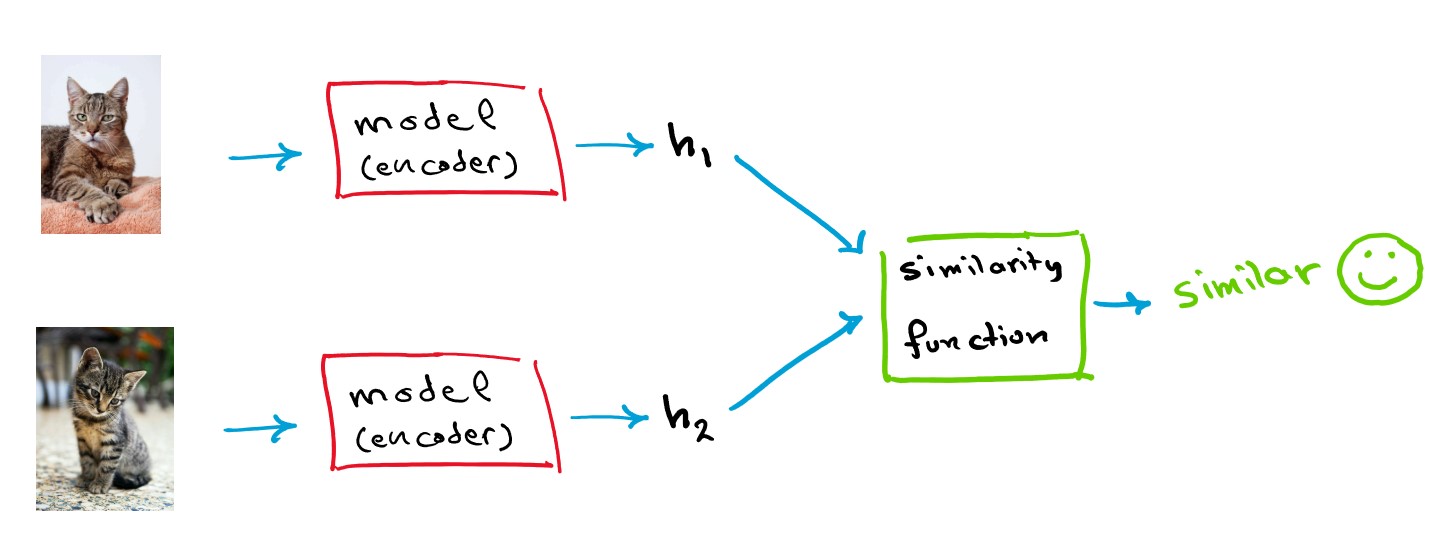
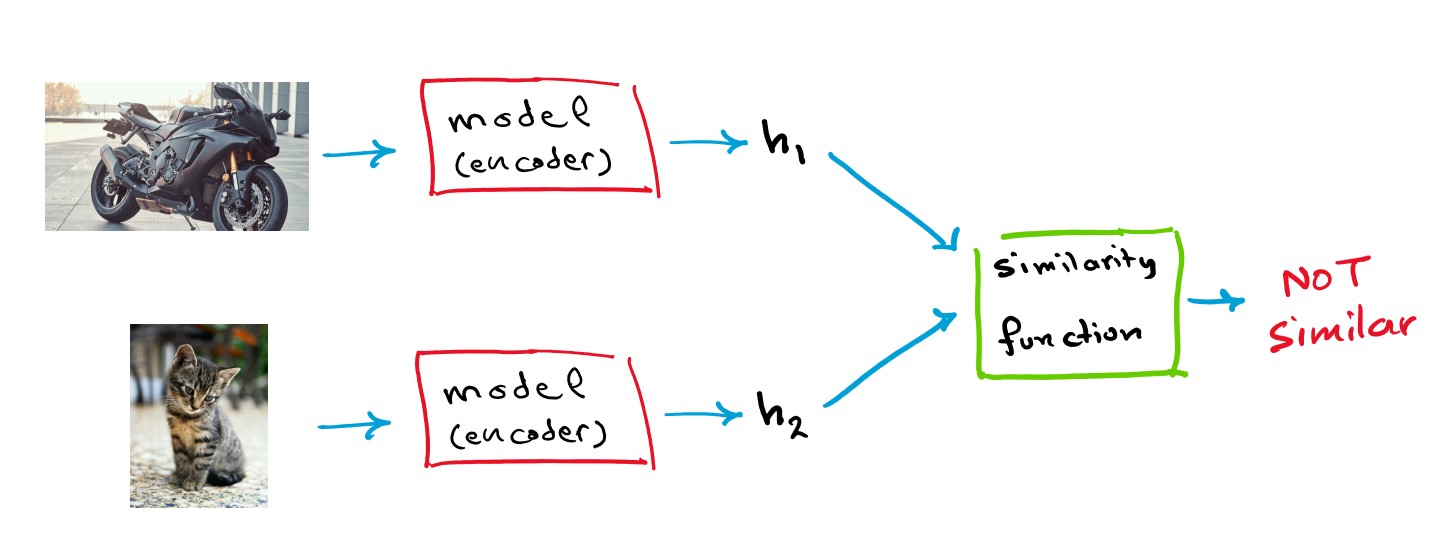
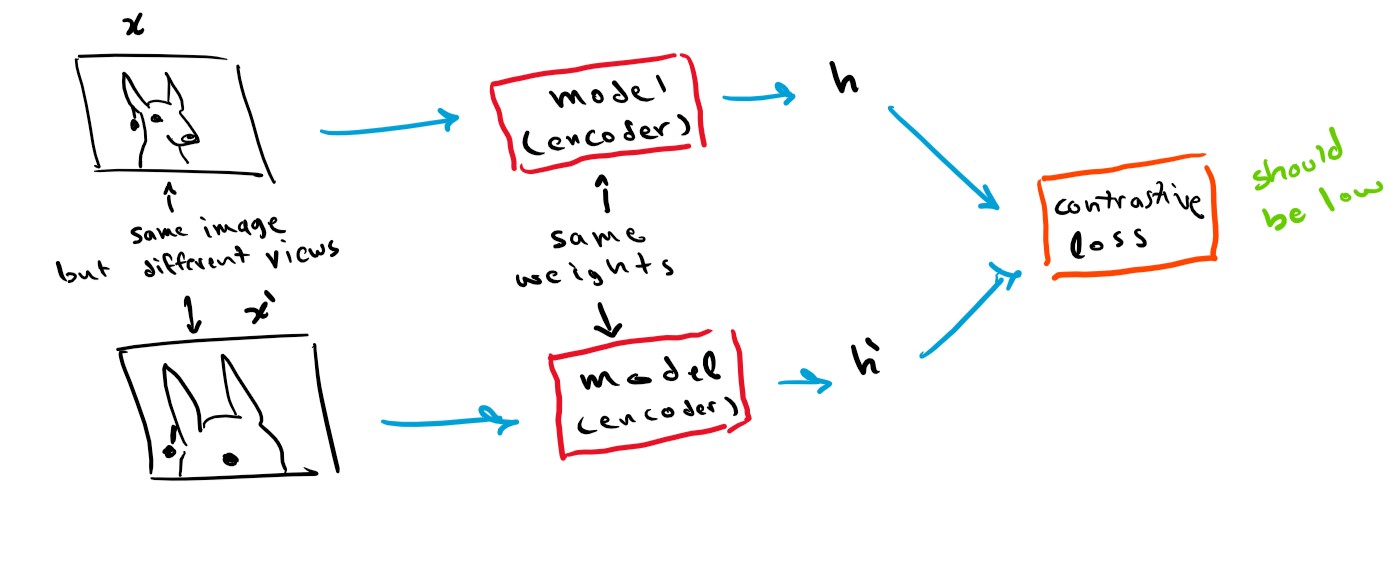
To generate good representation vectors for imagery data, the most popular approaches are contrastive and non-contrastive methods. The way contrastive methods work are by creating two neural networks with the same weights (identical networks) then feed one of the networks a picture x, then feed the other network a different view or a distorted version of x, let’s call it x’, the goal of the network is to create a vector representation h and h’ for both x and x’ that is almost identical since both x and x’ come from the same source image. This approach is prone to what is called “mode collapse” where the network will output h=constant for every x, x’, to combat this “negative sampling” is performed, where one network receives an image x and the other network receives a completely different image that we will call y, and the goal is to make sure the representation vectors are different since the images are different, such networks are called Siamese networks.
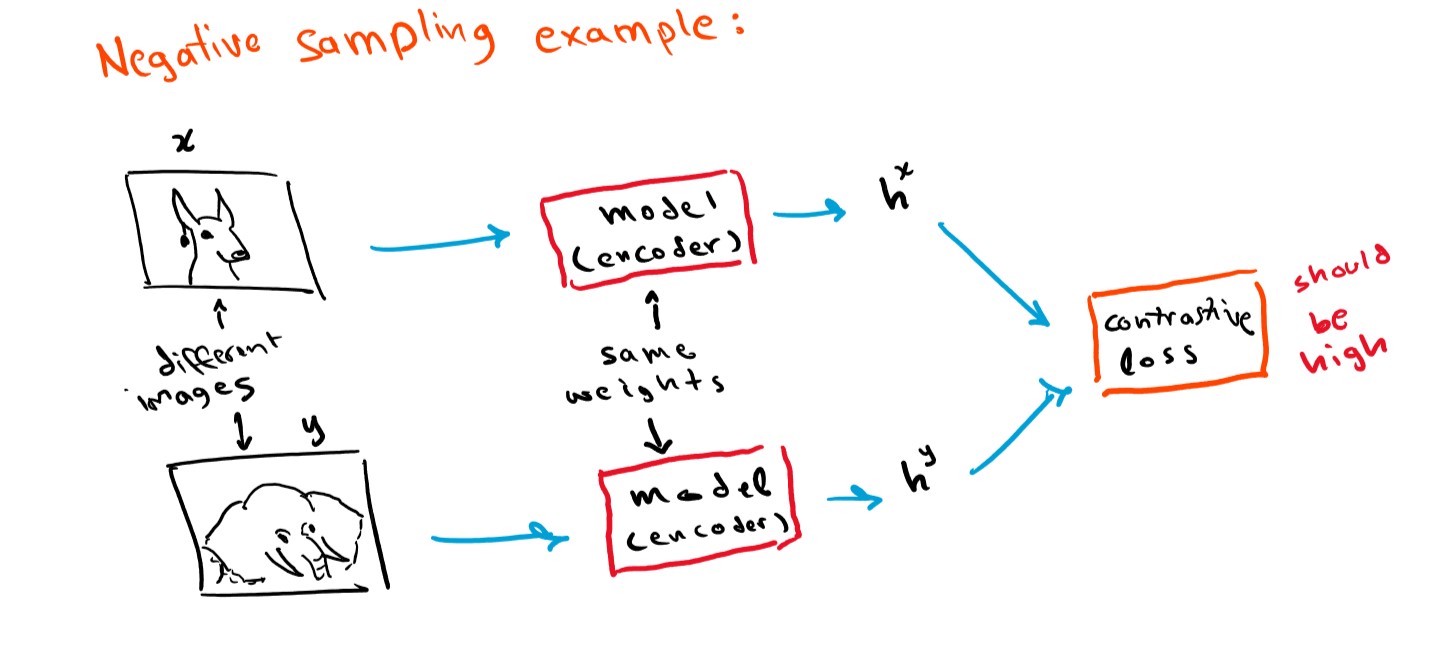
Negative sampling is very hard to perform, deciding which picture is considered “different” in a way that aids the representation task is difficult. That’s why other methods exist called Non-Contrastive methods, the main idea is very similar but without the negative sampling part, papers like BYOL and DINO (blog post and code coming soon for DINO’s paper stay tuned) are good examples for such methods.
I’d like to end this post with this exchange between Lex Fridman and Yann LeCun from Lex’s podcast:
Lex: Do you think it is possible that formulation alone (fill in the blanks approach) as a signal for self supervised learning can solve intelligence for vision and language?
Yann: I think this is our best shot at the moment.
Very useful resources on self supervised learning: Lex and Yann LeCun, Lex and Ishan Misra, this blog post and its explaination by Yannic Kilcher.